Part 1 - What are embeddings?
Part 1 in the Search and recommendations with embeddings series.
What are embeddings?
"Embeddings" are a representation of something using numbers. For words, images, songs, etc., we create a number to represent each item (e.g. [7], or several numbers together as a vector [2, 5, 3], . To create embeddings, we use Machine Learning approach called Representation Learning, which literally means learn how to represent an item with a number.
Terminology wise, creating a number to represent something, is more formally called "embedding an item in vector space." An embedding is composed of two things, a unique identifier for an item, and a vector. You can visualize a vector space as taking all of the vectors we've created, and plotting them onto a graph.
1-Dimensional Example: Fruit preference
For example, let's say we represented fruit on a 1-10 scale of how much I (Nelson) likes different fruits. Apples are 4.0, Nectarines are 8.1, Bananas are 6.5, and Mangosteens are 9.8. Those are my fruit embeddings, and they live in 1-dimensional vector space (1-dimensional here, refers to only using one number per fruit; vector space means all the numbers that I could rate fruit, in this case 1-10).
[ optional TODO: insert number line of fruit preferences ]
Each fruit embedding is composed of an identifier (the name of the fruit), and a vector (in this case, a vector of length 1 with a value of my rating). Within my fruit preference vector space, Apples and Mangosteens are the most different, as they are farthest apart. The distance between the fruits Mangosteen -> Apple, (9.8 - 4.0) = 5.8, is the largest.
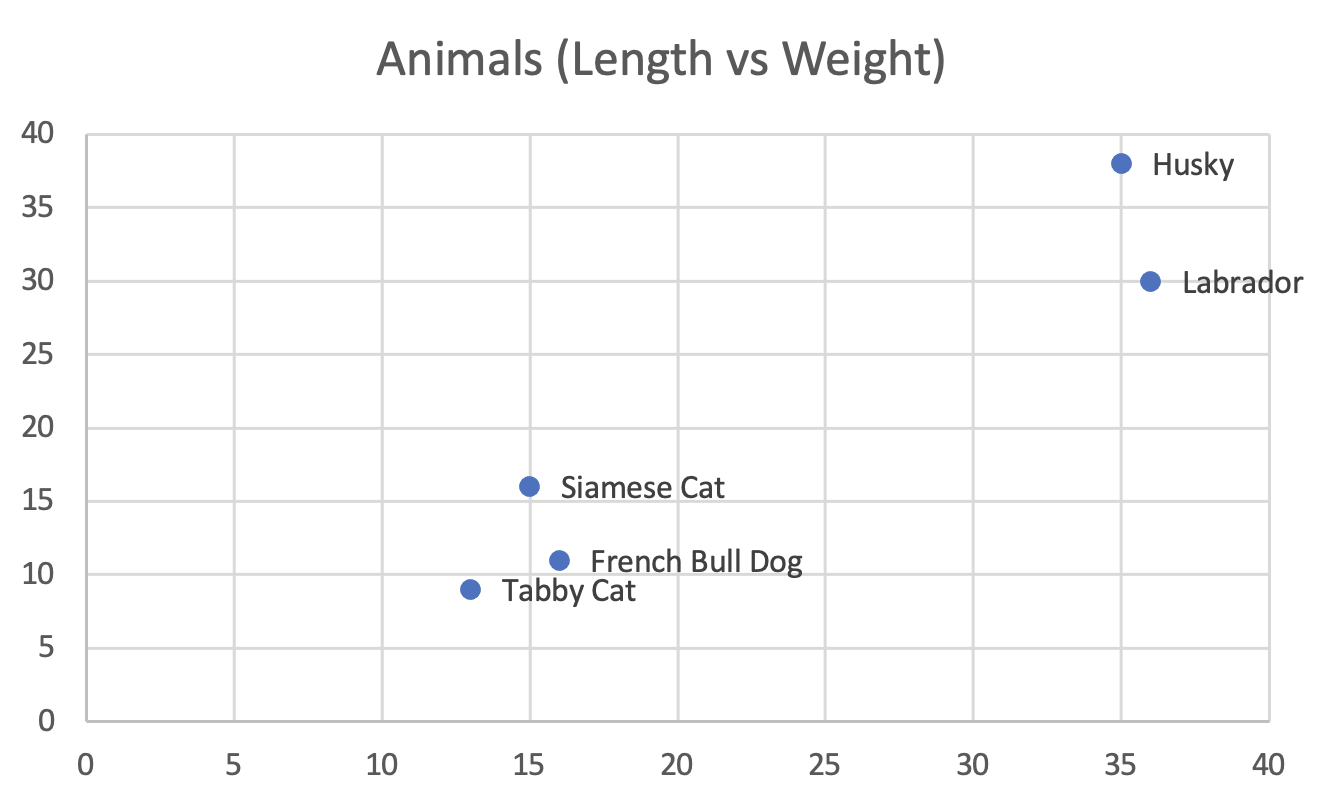
2-Dimensional Example: Animal size
To take another example, let's say we have dogs, and cats. We measure all the dogs and cats we encounter, noting their length and weight. We have now created embeddings for these animals, by embedding them in 2 dimensional vector space, using 2 numbers to represent each of them. The 2 dimensions of our animal vector are length, and weight. Our animal embeddings are below:
| Animal | Length (inches) | Weight (lbs) | |
|---|---|---|---|
| 1 | French Bull Dog | 15 | 16 |
| 2 | Husky | 35 | 38 |
| 3 | Labrador | 36 | 30 |
| 4 | Siamese Cat | 16 | 11 |
| 5 | Tabby Cat | 13 | 9 |
Here is the same Animal data from the table above, graphed, in 2 dimensional vector space. Vector here, means a value, e.g. a Husky has a vector of (35, 38).
300-Dimensional Example: word2vec
1 or 2-Dimensional embeddings are limited by their dimensionality in the amount of information they capture. Machine learning scientists and software engineers capture more information about items, by generating embeddings with larger dimensions.
A famous embeddings model for words was published by engineers at Google in 2013,. They learned embeddings for words by statistically analyzing a huge amount of written text. The model, called "word2vec", is 300-Dimensional, representing words as vectors (300 numbers per vector). E.g. Paris = [0.5, 1.2, -0.2, .... 297 more numbers] .
word2vec uses the idea that the meaning of a word can be learned by the company it keeps, thereby if 2 words are frequently beside each other in writing, they may be nearby in vector space.
A neat property of word2vec, is that although a word embedding is meaningless by itself (0.5, 1.2, -0.2 tells you nothing about Paris), in aggregate, word embeddings mean something. For example, taking the vectors for the following places, and placing them in the formula, researchers found France - Paris ~= Germany - Berlin , meaning there is some notion of a capital city learned in the model. And Queen - King ~= Woman - Man .
How many dimensions should there be?
From my own observation, of ML papers I’ve read, I’ve seen most researchers choose embeddings in the range of 100-5000 dimensions. Too many dimensions and you risk over-fitting, meaning essentially memorizing your input data, and too few dimensions, and your embeddings will not capture enough information to be useful.