Part 2 - What is K-Nearest Neighbors (KNN)?
Part 2 in the Search and recommendations with embeddings series.
An embedding's "nearest neighbors" are those other embeddings that are the shortest distance away in vector space.
Continuing the 2-Dimensional Example from Part 1: Animal size, let's say we measure an unknown animal, and we find its length to be 32 inches, and weight to be 33 lbs. With this information, we create the embedding Unknown Animal: (32, 33). We refer to this starting point as our basis embedding.
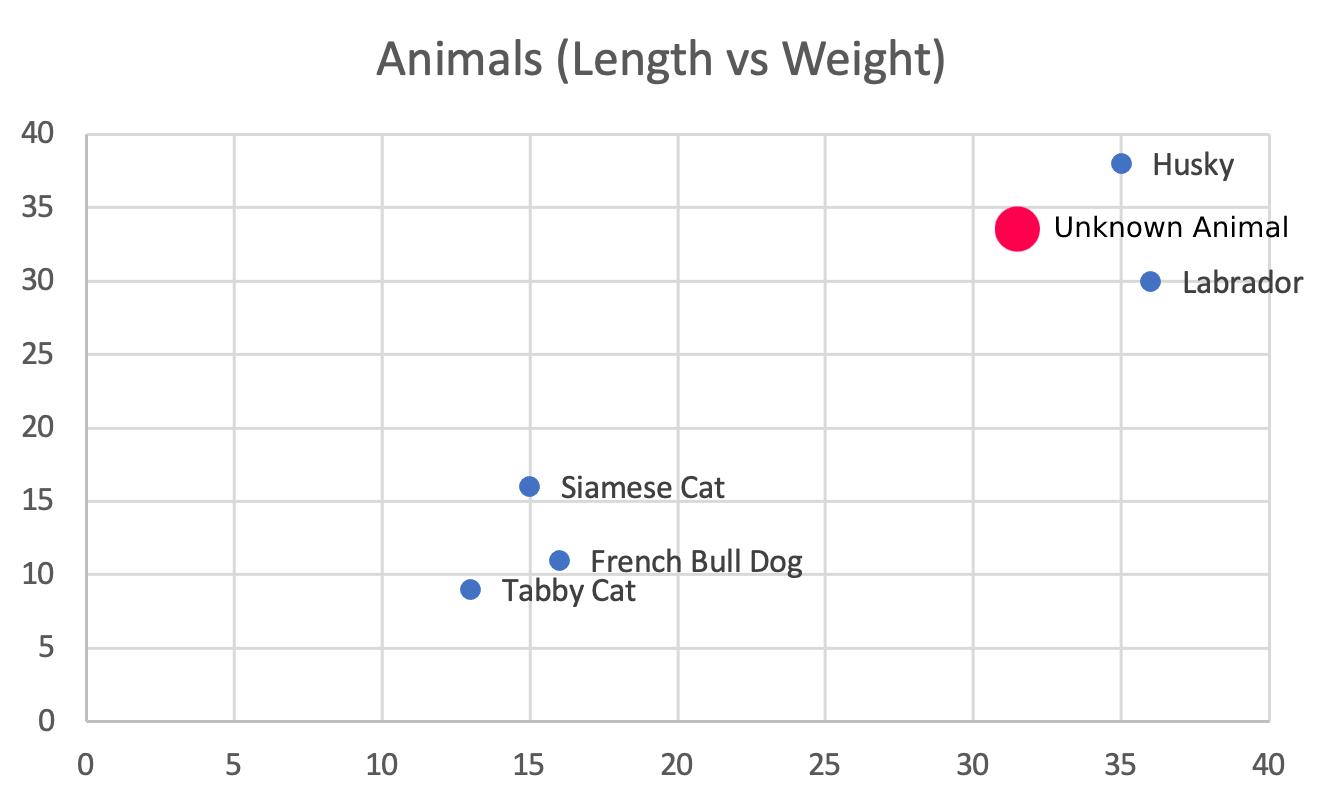
From the basis embedding Unknown Animal (32, 33), we can measure the distance between this vector (32, 33), and all the other animal points.
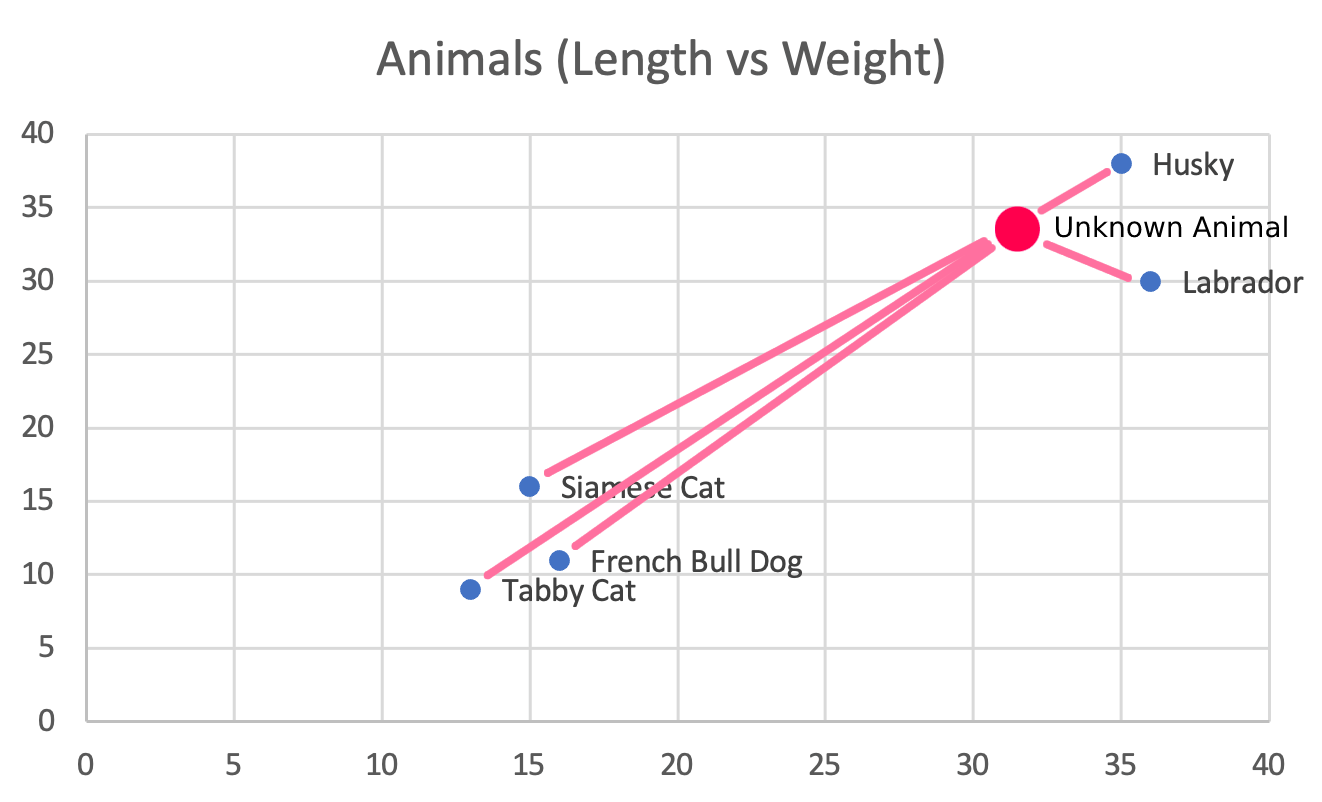
This (32, 33) animal is more likely to be similar to a Husky or Labrador than it is to the other animals, because Husky and Labrador are the 2 Nearest Neighbors to our new point.
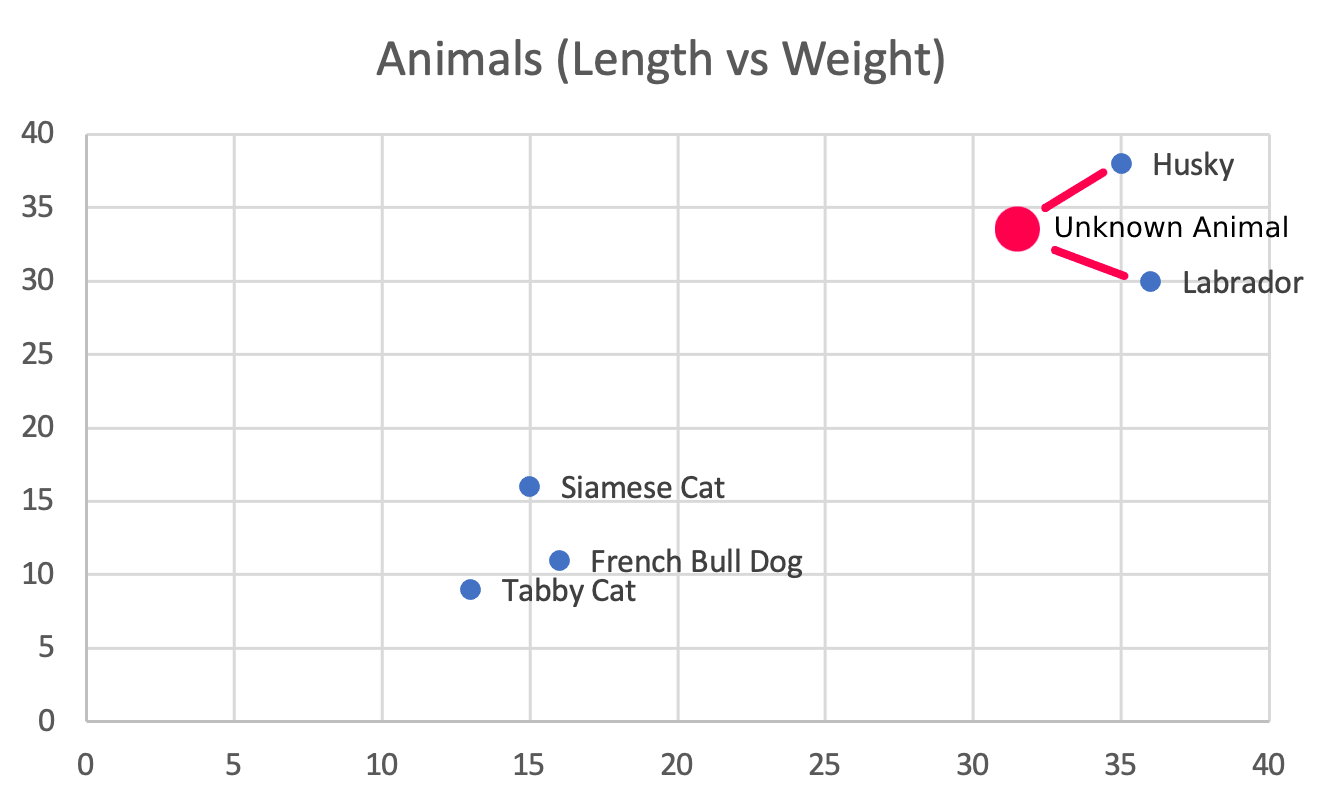
Terminology wise, KNN (K-Nearest Neighbors), is an abbreviation to refer to this calculation, where K is the number of nearest neighbor embeddings you want. In the above example, K=2. To say, K = 50, and do KNN, means find the 50 nearest neighbors to the basis embedding.
How do we calculate KNN?
There are multiple ways to calculate the distance between embeddings. The most obvious is regular “euclidean distance", which means treating vectors as points in space, and finding the distance between them, which we learned in geometry, √[ (x2 – x1)2 + (y2 – y1)2] .
In the above example, the distance from Unknown Animal to Husky is
√[ (35 – 32)2 + (38 - 33)2] ~= 5.83
Beyond euclidean distance, we can redefine "nearest" to be other mathematical operations. We can define it as the smallest angles between vectors (cosine simlarity), the largest projection of vectors onto one another (dot product), or the smallest number of squares to move on a chess board from one vector to another (Manhattan distance).
For our 2-Dimensional animal embeddings example, if two embeddings had a high cosine similarity (a small angle between them), that could express the idea that those animals have a similar length:width ratio. E.g. a Greyhound and a Corgi would have very different cosine similarities, but a Greyhound and a Greyhound puppy might have large cosine similarities. When doing KNN, if we used cosine similarity instead of Euclidean, we would find animals that have similar proportions, rather than animals have similar absolute sizes.
Said more abstractly, different distance functions will surface different nearest neighbors. Experimenting with your choice of distance functions will vary the neighbors you calculate.
Next up, in Part 3 - How do I choose a KNN Algorithm?, we discuss how to efficiently do all these distance calculations/vector math. Efficiency is especially important when you have a large number of embeddings and/or large number of embedding dimensionsions.